
We provide on this page the different artefacts which have been used and created when performing the case study concerning our EMISA submission.
Abstract
With new advances such as Cyber-Physical Systems (CPS) and Internet of Things (IoT), more and more discrete software systems interact with continuous physical systems.
State machines are a classical approach to specify the intended behavior of discrete systems during development. However, the actual realized behavior may deviate from those specified models due to environmental impacts, or measurement inaccuracies. Accordingly, data gathered at runtime should be validated against the specified model. A first step in this direction is to identify the individual system states of each execution of a system at runtime. This is a particular challenge for continuous systems where system states may be only identified by listening to sensor value streams. A further challenge is to raise these raw value streams on a model level for checking purposes.
To tackle these challenges, we introduce a model-driven runtime state identification approach. In particular, we automatically derive corresponding time-series database queries from state machines in order to identify system runtime states based on the sensor value streams of running systems. We demonstrate our approach for a subset of SysML and evaluate it based on a case study of a simulated environment of a five-axes grip-arm robot within a working station.
Architecture
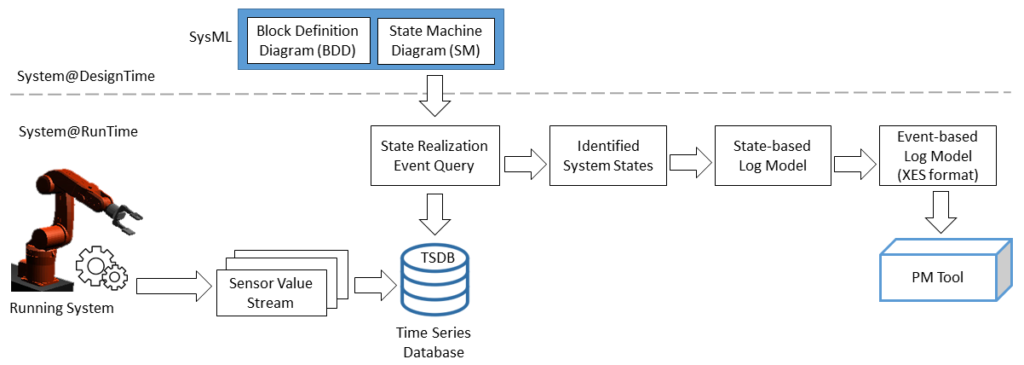
The figure above shows the architecture of Model-driven Runtime State IdEntification (MD-RISE) as well as the interplay of design time and runtime artefacts.
Case Study Description
For demonstration purpose, we developed a a simulation model of a gripper with angle sensors, which is executed by the open source tool Blender.
We deploy the scenario of a pick-and-place unit, where the gripper picks up different color-coded work pieces, place them on a test rig, picks the items up again and puts them down, depending on their red or green color, in two different storage boxes.
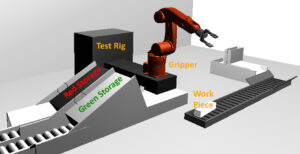
The simulation environment sends value streams of the sensors of the gripper during simulation to the time-series database InfluxDB. This technical set up was used as test input for the prototypical implementation of the MD-RISE approach. In Eclipse, we defined the metamodel for describing the gripper (consisting of properties and a state machine, where the desired behavior for runtime is described). Based on this metamodel we used Xtend to automatically derive time-series database queries. These queries are then executed to identify system states of the grippper. For evaluation purpose, we calculate the precision, recall and f-measure of our state identification approach.
Furthermore, the resulting states in the state-based log model are used as input model for our model-to-model transformation by ATL to transform it to a event-based log model, which can be used as input for the process mining tool ProM. Thus, the event-based log model can be analyzed and may help to uncover some under-specified or unintended parts of the process.
Downloads
- Eclipse project – Metamodel, Xtend, Evaluation
- Eclipse project – Performance Check only
- Eclipse project – Generate event-based log model
Running the Case Study
For running the case study, we recommend to use the Eclipse Modeling Edition. In the following we provide information on how to download, run and setup the Eclipse bundle for elaborating the case study. In addition, the time-series database InfluxDB is needed.
Download Eclipse
First you have to download the Eclipse Modeling Tools for your operating system and architecture. Once the download is finished, unzip the downloaded archive to any location you prefer. Please note, however, that the location should be writable without additional user permissions so that Eclipse may autonomously install updates and additional plug-ins. In addition, you need the extensions Xtend and ATL for executing the whole case study.
Run Eclipse
The prerequisite for running Eclipse is a current version of the Java Runtime Environment. Eclipse itself does not have to be “installed” per se. You may directly start Eclipse by running eclipse (.exe in case you use Windows). Select a workspace location according to your personal preferences.
Influx DB
Download the InfluxDB from InfluxData and start the server before you run the case study projects.